
WigtnOCR
ReleasedA 2B-parameter document parser that reads Korean government forms as accurately as a model 15x its size.
WigtnOCR distills a 30B teacher model into a 2B student through pseudo-label distillation and LoRA fine-tuning, achieving teacher-level accuracy on OmniDocBench while running on a single consumer GPU. Ranked #1 on the KoGovDoc Korean government document retrieval benchmark.
View on GitHubExisting OCR and rule-based parsers fail on Korean government documents — missing tables, forms, and complex layouts. State-of-the-art VLM parsers are optimized for English/Chinese, and 30B models are too expensive for production deployment.
Pseudo-label distillation compresses a 30B teacher's parsing intelligence into a 2B student via LoRA fine-tuning on 2,667 Korean government document pages, achieving #1 retrieval performance across 6 parsers.
Pseudo-Label Distillation
Compresses 30B teacher intelligence into a 2B student through pseudo-label distillation on 2,667 Korean government document pages.
LoRA Fine-tuning
LoRA rank=8 fine-tuning on all language model linear layers in just 31 minutes with DeepSpeed ZeRO-2.
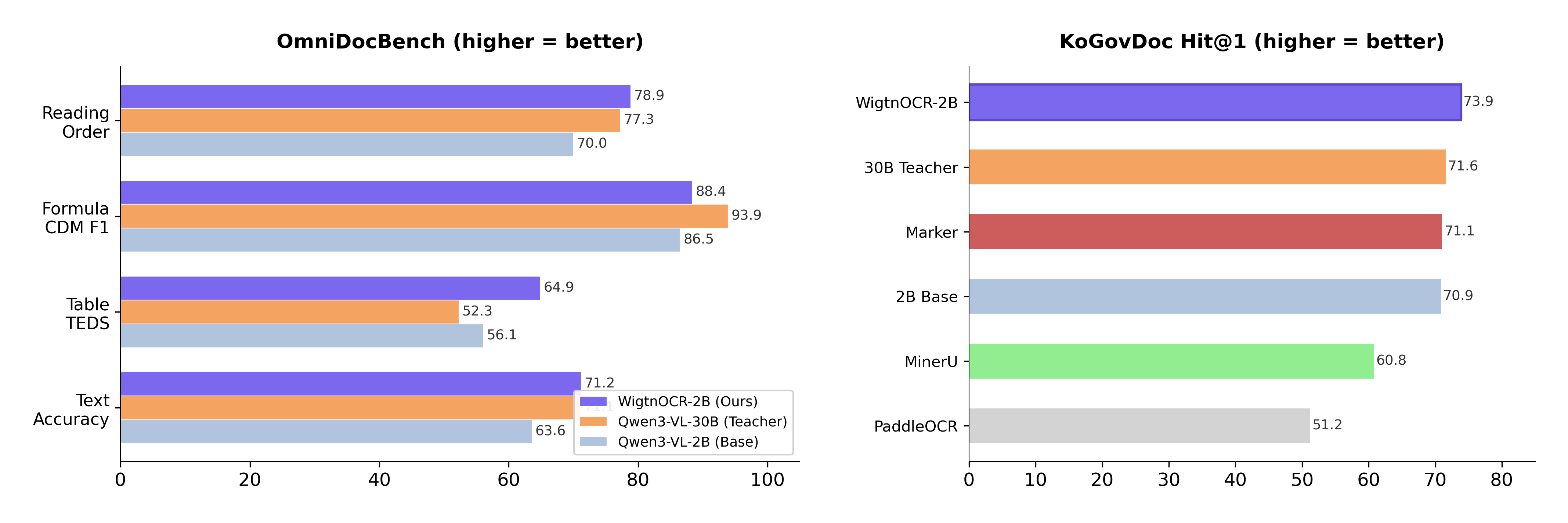
KoGovDoc-Bench
KoGovDoc-Bench — a new evaluation dataset of 294 Korean government document pages with pseudo-GT annotations.
Fully Open Source
Model weights, training data, and evaluation code all released on HuggingFace and GitHub.
Model & Training
Evaluation & Retrieval
Infrastructure
Overview
A VLM-based document parser specialized for Korean government documents. This research project originated from a practical need to parse Korean government public documents for a B2G (government-facing) RAG service. In a B2G environment where the end user's document structure is unknown in advance, the only certainty was the domain: Korean government public documents. The goal was to build an SLM-based document parser that could accurately read and structure these documents while meeting practical infrastructure constraints (limited GPU, cost).
Beyond the "bigger is better" paradigm, the central question in AI engineering today is: how to efficiently transfer LLM intelligence into SLMs. We applied the knowledge distillation paradigm pioneered by Orca (Microsoft, 2023) — training an SLM to learn from an LLM's reasoning process — to the domain of Korean government document parsing.
By LoRA fine-tuning Qwen3-VL-2B-Instruct on 2,667 Korean government document pages, WigtnOCR matches or exceeds a 15x larger Teacher model (30B) in parsing performance and ranks #1 in retrieval across 6 parsers, validating the end-to-end causal chain: "structured parsing → improved chunking → better retrieval." Model weights, training data, and evaluation code are all released as open source.
Key Results
- •2B model matches or exceeds a 15x larger 30B Teacher — 4/5 categories matched or exceeded
- •OmniDocBench Table TEDS — #1 (0.649)
- •6-parser retrieval comparison — Hit@1 and MRR@10 best performance
- •LoRA fine-tuning time — 31 minutes (DeepSpeed ZeRO-2)
- •Fully open-source — HuggingFace Model + Dataset + GitHub
Research Question
"Can we compress a 30B Teacher's parsing ability into a 2B Student while achieving specialized performance on Korean government documents? And does structured parsing actually lead to better chunking and retrieval quality in a real RAG pipeline?"
Technical Challenges — Why Existing Parsers Fall Short
Pure OCR Limitations: Traditional OCR tools like PaddleOCR can recognize text but fail to understand document structure. In our evaluation, they extracted 3-30x less text than WigtnOCR and missed most tables, forms, and complex layouts in Korean government documents.
Rule-based Parser Limitations: Rule-based parsers like PyMuPDF4LLM offer fast text extraction but near-zero structural recognition. They cannot preserve the hierarchical structure of legal articles (sections/clauses/items) or handle mixed layouts of tables, diagrams, and text.
Latest VLM Parser Limitations: State-of-the-art VLM parsers such as dots.ocr (RedNote) and olmOCR (AI2) are primarily trained on English and Chinese documents. They are not optimized for Korean government documents, which feature complex tables, forms, stamps, mixed scanned/digital pages, and multi-column layouts.
30B Model Deployment Limitations: While 30B-parameter VLMs deliver excellent parsing quality, they require dual GPUs and have slow inference, making production deployment difficult. A 2B model can be served on a single GPU with fast inference and realistic edge deployment.
Contribution Stack (3 Layers)
- •Layer 1 — Benchmark: KoGovDoc-Bench — a Korean government document evaluation set (294 validation pages with pseudo-GT)
- •Layer 2 — Fine-tuned Model: Wigtn/Qwen3-VL-2B-WigtnOCR — LoRA domain-adaptive fine-tuning weights (released on HuggingFace)
- •Layer 3 — Framework (Next Step): wigtnocr — a pip-installable OSS library providing a unified parsing → structured markdown → chunking pipeline (under development)
Pseudo-GT Pipeline
Stage 1 — Pseudo-GT Generation: PDF page images were fed to Qwen3-VL-30B-Instruct (Teacher) to generate structured markdown. A total of 4,501 pages were processed: 3,637 pages from 10 KoGovDoc documents + 864 pages from 39 arXiv papers. Initially, the 30B-Thinking model was used but produced unstable outputs (think tag contamination, token truncation), leading to a switch to the Instruct model. Finding: For document transcription, instruction-tuned models are more stable than reasoning models.
Stage 2 — GT Quality Verification: Qwen3.5-122B was used as a judge on a 5-point scale. Critically, evaluation was performed text-only without the original images — not asking "does this match the original?" but "is this output usable as training data?" This design prevents circular evaluation bias that would occur if a VLM evaluated another VLM's visual interpretation. A text-only LLM judge independently assesses structure, tables, completeness, hallucination, and consistency across 5 dimensions. Pass rate: KoGovDoc 75.1%, arXiv 73.8%. Pages scoring below 3 were excluded from training.
Stage 3 — Data Refinement: Document kogov_008 comprised 53% of all data — controlled via max_doc_ratio=0.25. Reasoning residue (English thought processes from the 30B-Thinking model) contaminating the GT was discovered — 20 pages deleted, 257 cleaned. Final dataset: train 2,667 + val 294 pages.
LoRA Fine-tuning
Base Model: Qwen3-VL-2B-Instruct. LoRA rank=8, alpha=32, targeting all linear layers in the language model. Vision Encoder and Aligner were frozen — a pilot test confirmed the VLM's visual recognition was sufficient (Structure F1 79%) but text generation accuracy was lacking.
- •Hardware: 2x NVIDIA RTX PRO 6000 Blackwell (96GB each)
- •DeepSpeed ZeRO-2, training time 31 minutes, final loss 0.075
| Config | LoRA r | Epochs | Text NED↓ | TEDS↑ | TEDS-S↑ | CDM F1↑ | RO NED↓ | Skip%↓ | Verdict |
|---|---|---|---|---|---|---|---|---|---|
| v1 (Final) | 8 | 3 | 0.288 | 0.649 | 0.732 | 0.884 | 0.211 | 5.8% | Best overall |
| v2-best | 32 | 3 | 0.309 | 0.600 | 0.697 | — | 0.215 | 0.7% | Table regression |
| v2-last | 32 | 5 | 0.306 | 0.610 | 0.695 | 0.892 | 0.214 | 0.0% | Overfitting |
Finding: LoRA rank 8 outperformed rank 32 — increasing rank slightly improved formulas but degraded table performance (-4.9pp) and text (+2.1pp). Epoch 5 showed overfitting via rising val loss. v2 achieved 0% skip rate but at the cost of core parsing quality, so v1 was selected as the final model.
OmniDocBench Evaluation
Evaluated on OmniDocBench (CVPR 2025) — 1,355 PDF pages with human-annotated ground truth — comparing 4 models.
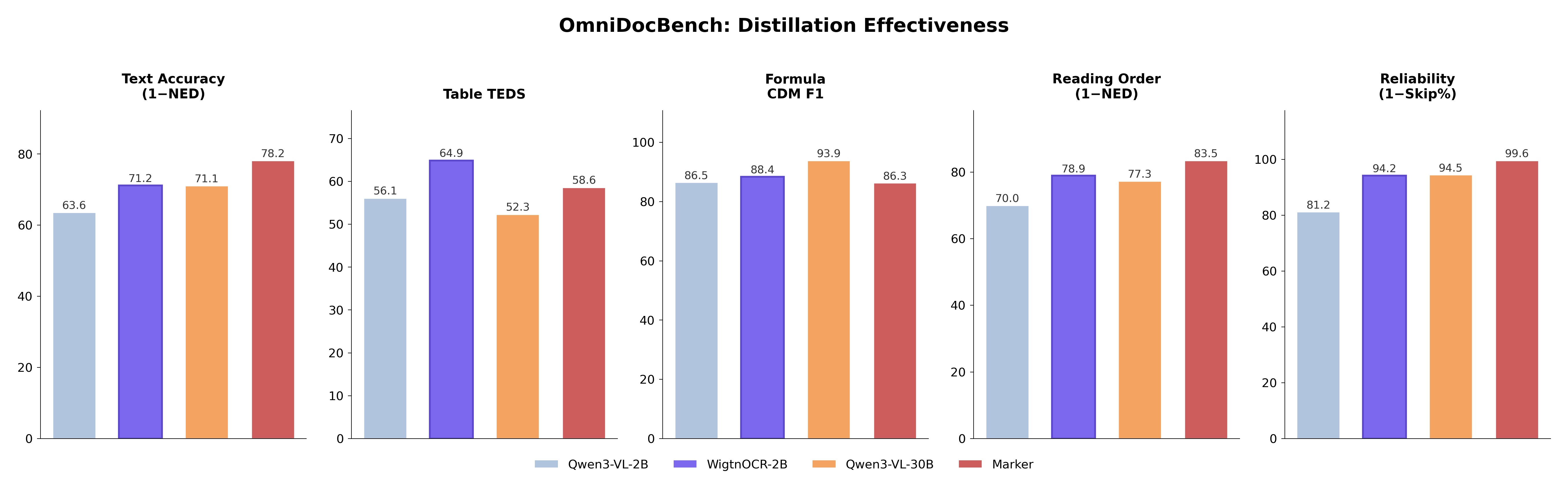
| Model | Text NED↓ | Table TEDS↑ | TEDS-S↑ | CDM F1↑ | CDM Exp↑ | RO NED↓ | Skip%↓ |
|---|---|---|---|---|---|---|---|
| Qwen3-VL-30B (Teacher) | 0.289 | 0.523 | 0.657 | 0.939 | 0.692 | 0.227 | 5.5% |
| Qwen3-VL-2B (Base) | 0.364 | 0.561 | 0.667 | 0.865 | 0.504 | 0.300 | 18.8% |
| Marker (Rule-based) | 0.218 | 0.586 | 0.658 | 0.863 | 0.582 | 0.165 | 0.4% |
| WigtnOCR v1 (Ours) | 0.288 | 0.649 | 0.732 | 0.884 | 0.600 | 0.211 | 5.8% |
- •Text NED: Matches 30B Teacher (0.288 vs 0.289)
- •Table TEDS: Overall #1 — 0.649 (vs Teacher's 0.523, +12.6pp)
- •Reading Order: Exceeds 30B Teacher (0.211 vs 0.227)
- •vs Base 2B — Text NED +21%, Table TEDS +16%, Reading Order +30%
- •Student matches or exceeds 30B Teacher in 4/5 categories — validating pseudo-label distillation
KoGovDoc Val Evaluation
Full-page text NED evaluation on 294 validation pages excluded from training.
| Model | NED↓ | Eval Success | Errors |
|---|---|---|---|
| WigtnOCR v1 | 0.285 | 289/294 | 5 |
| Qwen3-VL-30B (Teacher) | 0.334 | 294/294 | 0 |
| Qwen3-VL-2B (Base) | 0.390 | 294/294 | 0 |
WigtnOCR exceeds the 30B Teacher on Korean government documents (NED 0.285 vs 0.334), demonstrating effective domain-specific knowledge transfer.
Chunking Quality & Retrieval Evaluation
To verify whether "structured parsing actually produces better chunks," we evaluated 6 parsers using the BC/CS metrics from MoC (ACL 2025). Semantic chunking (BGE-M3) was used as the primary comparison strategy — both parsers chunk using the same method, with only the input text's structural quality differing, ensuring a fair comparison.
| Model | BC↑ | CS↓ |
|---|---|---|
| MinerU | 0.735 | 2.711 |
| WigtnOCR-2B | 0.706 | 2.859 |
| Qwen3-VL-30B | 0.714 | 3.164 |
| Marker | 0.683 | 3.206 |
| Qwen3-VL-2B | 0.678 | 3.446 |
| PaddleOCR | 0.654 | 3.420 |
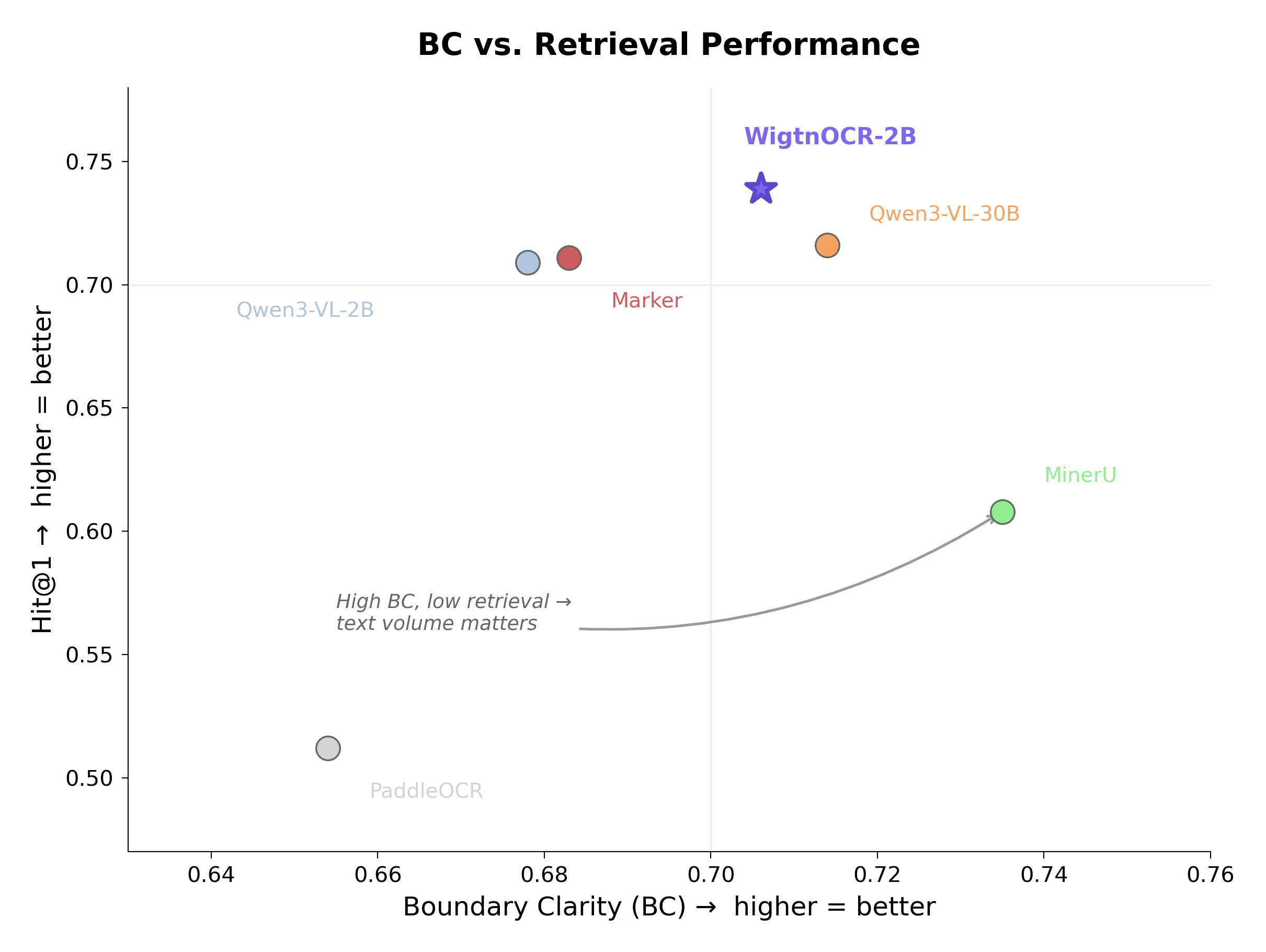
BC/CS quality doesn't guarantee retrieval performance. Stage 8 measures the final retrieval performance to complete the causal chain. Pipeline: Semantic chunking → BGE-M3 vectorization → FAISS search, evaluated on 564 queries.
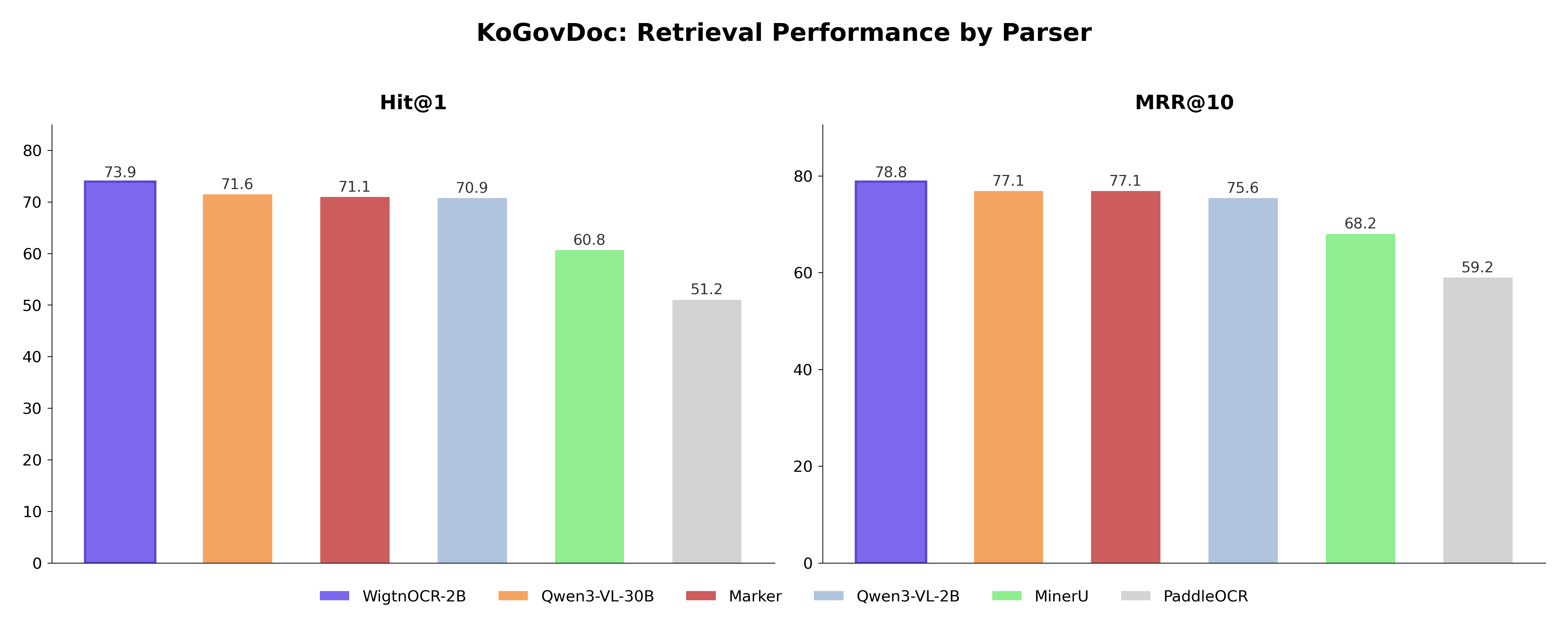
| Model | Hit@1↑ | Hit@5↑ | MRR@10↑ | nDCG@10↑ |
|---|---|---|---|---|
| WigtnOCR-2B | 0.739 | 0.855 | 0.788 | 0.437 |
| Qwen3-VL-30B | 0.716 | 0.839 | 0.771 | 0.411 |
| Marker | 0.711 | 0.853 | 0.771 | 0.412 |
| Qwen3-VL-2B | 0.709 | 0.814 | 0.756 | 0.444 |
| MinerU | 0.608 | 0.789 | 0.682 | 0.384 |
| PaddleOCR | 0.512 | 0.693 | 0.592 | 0.293 |
- •WigtnOCR ranks #1 in Hit@1 (0.739), Hit@5 (0.855), and MRR@10 (0.788)
- •vs PaddleOCR: Hit@1 +22.7pp; vs 30B Teacher: +2.3pp
- •MinerU is BC/CS #1 but Retrieval #5 — chunk boundary quality doesn't predict retrieval; text richness and structural fidelity matter more for end-to-end RAG performance
Practical Findings
- •Thinking vs Instruct: For document transcription, reasoning models produce unstable output (think tag contamination, token truncation). Instruction-tuned models are more reliable.
- •LoRA Rank Sweet Spot: With 2,667 training samples, r=8 is optimal. Increasing to r=32 degrades table performance by -4.9pp.
- •BC/CS ≠ Retrieval: BC/CS chunk quality metrics do not predict retrieval performance. MinerU ranks #1 in BC/CS but #5 in retrieval. Text richness and structural fidelity are more important for end-to-end RAG.
- •CS O(n²) Solution: MAX_CHUNKS_FOR_CS=50 with uniform sampling maintains representativeness while bounding computation.
- •Page → Document Aggregation: Page-level chunking produced too few chunks for BC/CS calculation. Switching to document-level aggregation resolved this.
- •VLM Text Extraction Volume: WigtnOCR extracts 3-30x more text than PaddleOCR, capturing tables, forms, and complex layouts that pure OCR misses.