WIGVO
LiveBreak language barriers in Korea. Call anyone, in any language.
Real-time voice translation for phone calls. Powered by dual AI sessions and software-only echo cancellation, WIGVO lets you call any phone number in any language. The other person just answers a normal call — no app needed.
View on GitHubK-Culture brought millions to Korea — but when they need to make a phone call, the language wall hits hard. Booking a restaurant, calling a hospital, reaching a landlord — everyday calls that locals handle in seconds become impossible without Korean. And Koreans living abroad face the same wall in reverse.
WIGVO bridges the gap with real-time phone translation. Our dual-session architecture runs two parallel AI interpreters — one for each speaker — delivering natural, bidirectional voice translation over standard phone lines.
Dual Session Architecture
Two parallel OpenAI Realtime sessions handle each side of the conversation independently, ensuring natural turn-taking.
Any Phone, Any Language
Call any phone number on any carrier. Works with landlines, mobile phones, and VoIP — the recipient doesn't need any app.
Echo Cancellation
Software-only echo cancellation eliminates feedback loops without hardware, keeping conversations natural.
No App Required
The person you're calling just answers their phone normally. Zero setup, zero downloads on their end.
Voice-to-Voice
Speak naturally in your language. WIGVO translates your voice in real-time and delivers it as natural speech to the other person — and vice versa.
Text-to-Voice
Type what you want to say, and WIGVO speaks it to the other person in their language. Perfect for noisy environments or precise messages.
AI Agent
Let WIGVO's AI agent handle the call for you. Describe what you need — book a reservation, schedule an appointment — and the agent makes the call.
AI & Audio
Backend & Frontend
Infrastructure
Who Is This For?
- •Foreign residents in Korea: 2.2 million residents (2024) who cannot make phone calls in Korean
- •Koreans living abroad: 2.8 million overseas Koreans who cannot call in the local language
- •Hearing and speech impaired: 390,000 registered individuals for whom voice calls are inaccessible
- •Call-phobic generation: ~40% of Gen MZ who avoid phone calls entirely
Technical Challenges — Why PSTN Is Hard
Audio Quality Gap: High-bandwidth environments (16-24kHz PCM16) assume wideband audio and client-side AEC. PSTN operates on G.711 μ-law 8kHz narrowband codec with 80-600ms variable delay and constant codec compression noise.
Echo Loop: AI-translated TTS audio returns through the PSTN after 80-600ms, re-entering the STT → translation → TTS pipeline in an infinite loop. 8 out of 10 initial test calls experienced this. Without client-side AEC available in high-bandwidth app environments, PSTN requires a software-only solution.
VAD Failure: OpenAI Server VAD assumes clean wideband audio. PSTN background noise (RMS 50-200) registers as "speech in progress" to Server VAD, causing speech_stopped to fire 15-72 seconds late or not at all.
| System | PSTN | Bidirectional | S2S | Echo Handling | Accessibility |
|---|---|---|---|---|---|
| SeamlessM4T | O | O | N/A | ||
| Moshi / Hibiki | O | N/A | |||
| Google Duplex | O | N/D | |||
| Samsung Galaxy AI | O | O | O | HW AEC | |
| SKT A.dot | O | O | O | Carrier Infra | |
| WIGVO | O | O | O | Software | O |
Architecture — Dual-Session Echo Gating
When a browser client connects via WebSocket to the relay server, the server manages 2 independent Realtime LLM sessions and a Twilio phone gateway. An AudioRouter delegates events to one of 3 pipelines (V2V, T2V, FullAgent) via the Strategy pattern.
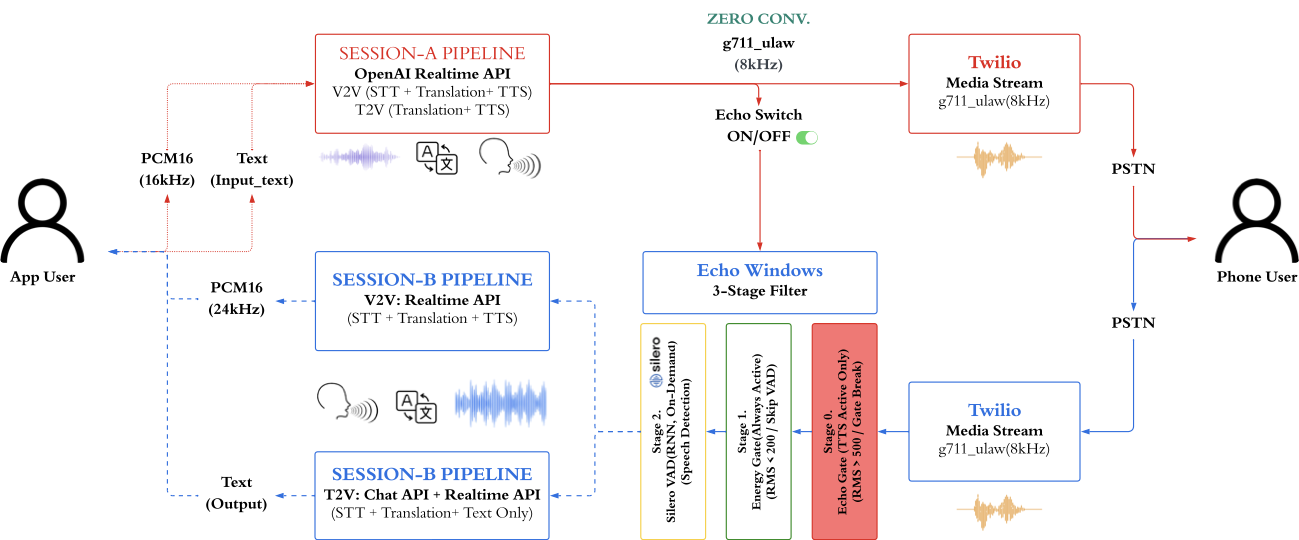
- •Layer 1 — Transport: Twilio Media Streams (PSTN ↔ G.711 μ-law 8kHz) + Browser WebSocket (PCM 16kHz)
- •Layer 2 — Pipeline: AudioRouter delegates events to V2V / T2V / Agent mode via Strategy pattern
- •Layer 3 — Sessions: Session A (browser→phone) + Session B (phone→browser) maintain independent system prompts and 6-turn sliding context
STT-Translation Separation: Delegating translation to the Realtime API causes hallucinations that add content not present in the original speech. STT uses Realtime API's built-in Whisper-1, while translation is handled by GPT-4o-mini Chat API (temperature=0). context_prune_keep=0 completely blocks the Realtime API's own translation.
Echo Gate (7-Stage Evolution)
Blocks the echo loop where TTS audio returns through PSTN.
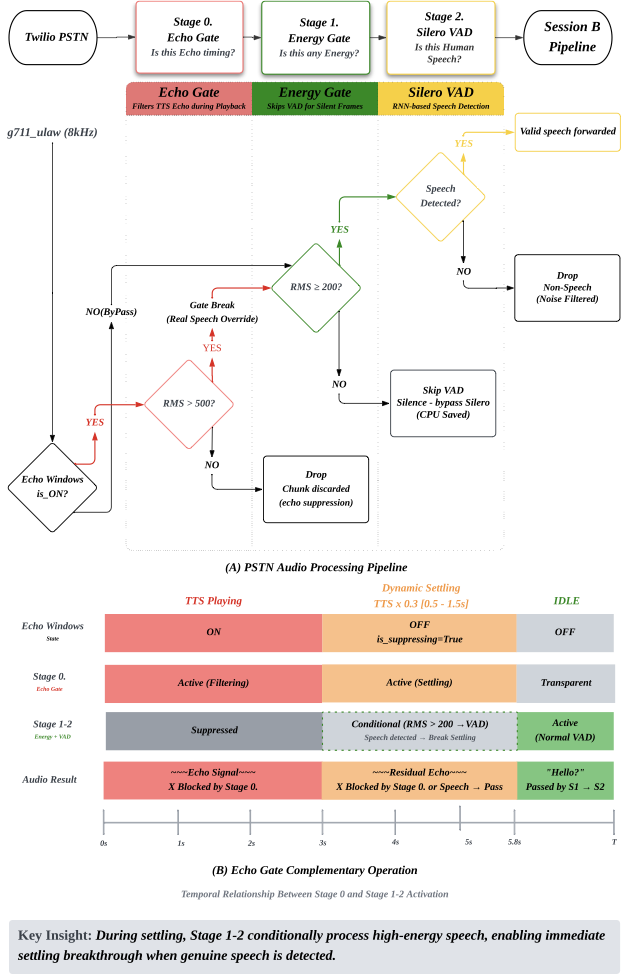
The Critical Breakthrough — Drop vs Replace: "Dropping" audio causes Server VAD to interpret it as a stream interruption and freeze. "Replacing" with μ-law silence (0xFF) maintains stream continuity while VAD correctly recognizes it as silence. This "Drop vs Replace" paradigm is the core principle applied consistently across both Echo Gate and VAD.
- •Echo Window: Replaces PSTN audio with μ-law silence during TTS playback + 0.5s jitter margin after TTS ends
- •Dynamic Settling: TTS length × 0.3 (clamped 0.5s-1.5s) suppresses AGC recovery noise; RMS ≥ 500 passes through as real speech
- •Normal Window: RMS ≥ 150 energy threshold
7-Stage Evolution: (1) Audio Fingerprint via Pearson correlation — failed completely due to G.711 μ-law nonlinear quantization destroying correlation. (2) Fixed 2.5s Echo Gate — solved echo but disrupted conversation flow. (3) Dynamic Cooldown — proportional to TTS length, but AGC noise spike after gate release. (4) Final: Silence Injection + RMS + Dynamic Settling + Silero.
Result: Echo loop rate reduced from 8/10 initial calls → 0/148 production calls.
PSTN VAD — Independent Architecture
OpenAI Server VAD is a black box with no frame-level control during echo windows. RMS thresholds of 150→80→30→20 were all attempted, but no single stable threshold exists for PSTN. The solution: switch to local Silero VAD with a PSTN-specific independent architecture.
- •Stage 1 — RMS Energy Gate: Echo window RMS ≥ 500, Settling RMS ≥ 200, Normal RMS ≥ 150
- •Stage 2 — Silero VAD: Neural network judgment on frames passing the energy gate. 8kHz → 16kHz zero-order hold upsampling
- •Asymmetric hysteresis: onset 160ms (5 frames) / offset 800ms (25 frames)
- •Minimum utterance 250ms, minimum peak RMS 300 to reject weak signals as noise
Result: speech_stopped latency reduced from 15-72 seconds → 480ms.
Whisper Hallucination Filter
When PSTN noise enters Whisper-1, it generates "plausible" text learned from training data (YouTube, broadcasts). Broadcast-style patterns like "MBC News, this is Lee Deokyoung" and "Thanks for watching" leaked into the translation pipeline and actually reached recipients' phones in production.
- •Pre-STT (Stage 0): Echo Gate + Silence Injection prevents contaminated audio from reaching Whisper
- •Post-STT (Stage 1): 29 Korean + 22 English = 51 broadcast-style blocklist patterns + 4-layer text filter (min length, silence timeout, repeated phrases, confidence score)
- •Post-Translation (Stage 2): 3-level Guardrail: L1 (pass, 0ms) · L2 (immediate TTS + background correction, 0ms) · L3 (block + GPT-4o-mini correction, ~800ms)
Result: Hallucination leak rate below 0.3%, average 0.7 blocks per call (148 calls). 95%+ cases handled by L1 with zero additional latency.
Strategy Pattern — 3 Communication Pipelines
The initial monolithic AudioRouter was refactored into a thin delegator + 3 independent pipelines via the Strategy pattern (73% code reduction).
- •VoiceToVoice (V2V): Bidirectional voice translation. Echo Gate + Silence Injection + 3-tier interrupt priority
- •TextToVoice (T2V): For hearing/speech-impaired users. Text input → AI-translated voice delivery
- •FullAgent: AI proxy calling for call-phobic users. Inherits TextToVoice + Function Calling
- •EchoGateManager: Shared echo prevention logic across pipelines
- •ChatTranslator: T2V/Agent Session B translation via GPT-4o-mini
Key Metrics — 148 Production Calls
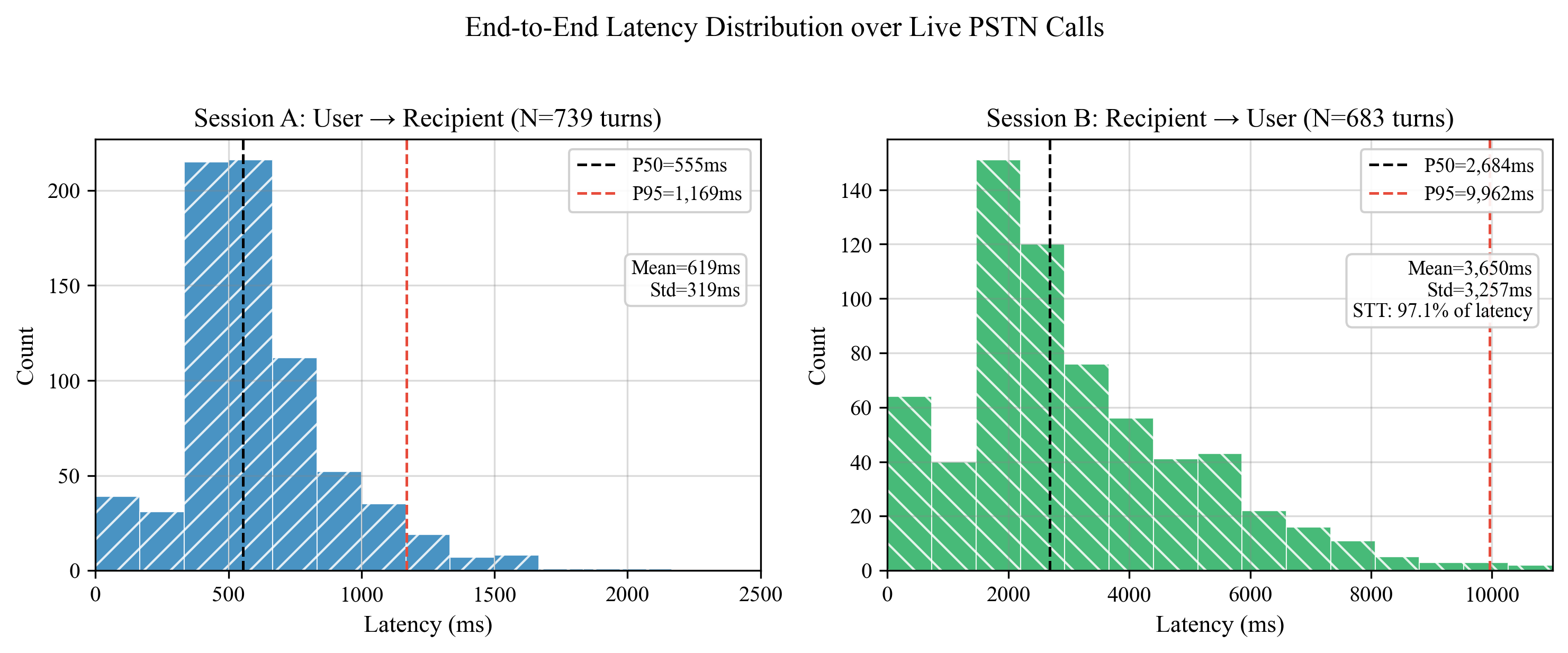
Latency:
- •Session A P50: 555ms / P95: 1,169ms
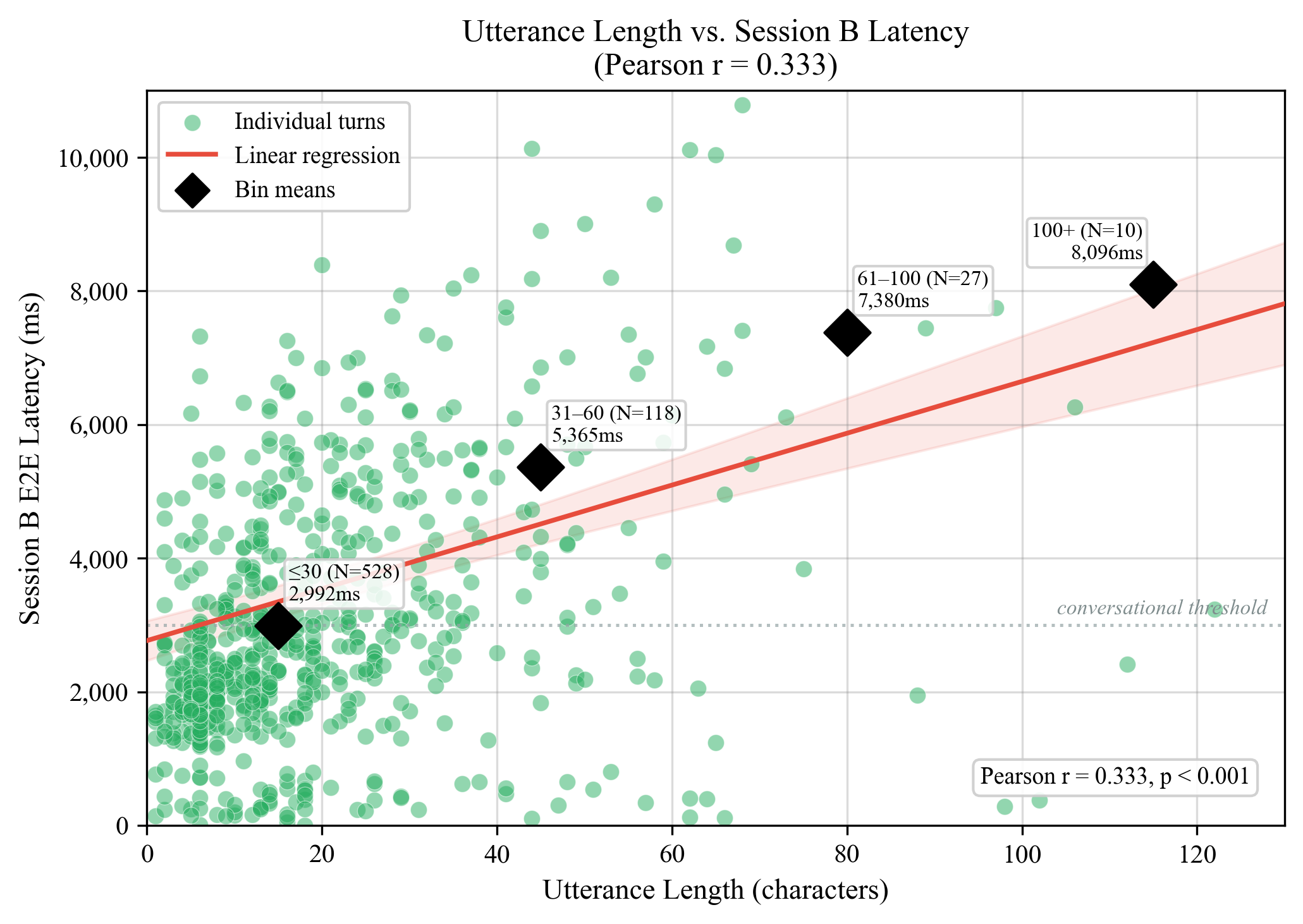
- •Session B P50: 2,868ms (correlated with utterance length, Pearson r=0.400)
- •First message P50: 1,215ms (cold start)
Echo & Safety:
- •Echo loops: 0 / 148 calls (prototype 80% → 0%)
- •Echo gate activations per call: avg 7.0
- •VAD false positives per call: avg 1.8
- •Hallucination blocks per call: avg 0.7
- •Guardrail L2: 148 (normal corrections) / L3: 0
Cost:
- •V2V: $0.30/min · T2V: $0.29/min
- •After architecture optimization: $0.18/min (33% reduction)
- •Mode distribution: T2V 116 calls (68.6%) · V2V 52 calls (30.8%) · Agent 1 call (0.6%)
Latency Distribution
Ablation Study
| Method | Echo Loop | Conversation Delay | Adopted |
|---|---|---|---|
| Audio Fingerprint (Pearson) | Unresolved | — | |
| Fixed Echo Gate (2.5s) | Resolved | Disrupted | |
| Dynamic Cooldown | Resolved | Improved | |
| Silence Injection + RMS + Dynamic Settling + Silero | Resolved | Minimized | O |
Finding: In PSTN environments, signal correlation-based echo detection does not work. Only direct control of echo windows with silence frame replacement is stable. The Realtime API's generation characteristics are suitable for STT but not for translation — separating translation to a temperature=0 Chat API improves both accuracy and stability.